Using Celery With Flask
Posted by
on under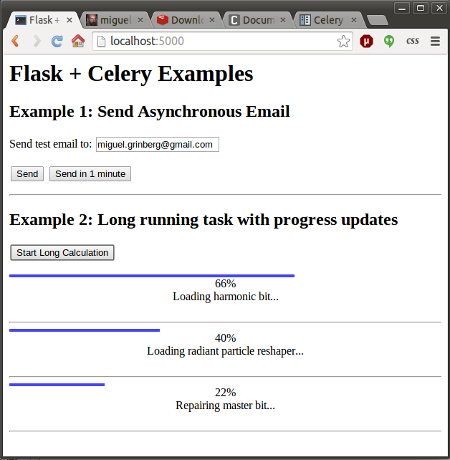
The topic of running background tasks is complex, and because of that there is a lot of confusion around it. I have tackled it in my Mega-Tutorial, later in my book, and then again in much more detail in my REST API training video. To keep things simple, in all the examples I have used so far I have executed background tasks in threads, but I always noted that for a more scalable and production ready solution a task queue such as Celery should be used instead.
My readers constantly ask me about Celery, and how a Flask application can use it, so today I am going to show you two examples that I hope will cover most application needs.
What is Celery?
Celery is an asynchronous task queue. You can use it to execute tasks outside of the context of your application. The general idea is that any resource consuming tasks that your application may need to run can be offloaded to the task queue, leaving your application free to respond to client requests.
Running background tasks through Celery is not as trivial as doing so in threads. But the benefits are many, as Celery has a distributed architecture that will enable your application to scale. A Celery installation has three core components:
- The Celery client. This is used to issue background jobs. When working with Flask, the client runs with the Flask application.
- The Celery workers. These are the processes that run the background jobs. Celery supports local and remote workers, so you can start with a single worker running on the same machine as the Flask server, and later add more workers as the needs of your application grow.
- The message broker. The client communicates with the the workers through a message queue, and Celery supports several ways to implement these queues. The most commonly used brokers are RabbitMQ and Redis.
For The Impatient
If you are the instant gratification type, and the screenshot at the top of this article intrigued you, then head over to the Github repository for the code used in this article. The README file there will give you the quick and dirty approach to running and playing with the example application.
Then come back to learn how everything works!
Working with Flask and Celery
The integration of Celery with Flask is so simple that no extension is required. A Flask application that uses Celery needs to initialize the Celery client as follows:
from flask import Flask
from celery import Celery
app = Flask(__name__)
app.config['CELERY_BROKER_URL'] = 'redis://localhost:6379/0'
app.config['CELERY_RESULT_BACKEND'] = 'redis://localhost:6379/0'
celery = Celery(app.name, broker=app.config['CELERY_BROKER_URL'])
celery.conf.update(app.config)
As you can see, Celery is initialized by creating an object of class Celery, and passing the application name and the connection URL for the message broker, which I put in app.config under key CELERY_BROKER_URL. This URL tells Celery where the broker service is running. If you run something other than Redis, or have the broker on a different machine, then you will need to change the URL accordingly.
Any additional configuration options for Celery can be passed directly from Flask's configuration through the celery.conf.update() call. The CELERY_RESULT_BACKEND option is only necessary if you need to have Celery store status and results from tasks. The first example I will show you does not require this functionality, but the second does, so it's best to have it configured from the start.
Any functions that you want to run as background tasks need to be decorated with the celery.task decorator. For example:
@celery.task
def my_background_task(arg1, arg2):
# some long running task here
return result
Then the Flask application can request the execution of this background task as follows:
task = my_background_task.delay(10, 20)
The delay() method is a shortcut to the more powerful apply_async() call. Here is the equivalent call using apply_async():
task = my_background_task.apply_async(args=[10, 20])
When using apply_async(), you can give Celery more detailed instructions about how the background task is to be executed. A useful option is to request that the task executes at some point in the future. For example, this invocation will schedule the task to run in about a minute:
task = my_background_task.apply_async(args=[10, 20], countdown=60)
The return value of delay() and apply_async() is an object that represents the task, and this object can be used to obtain status. I will show you how this is done later in this article, but for now let's keep it simple and not worry about results from tasks.
Consult the Celery documentation to learn about many other available options.
Simple Example: Sending Asynchronous Emails
The first example that I'm going to show is a very common need of applications: the ability to send emails without blocking the main application.
For this example I'm going to use the Flask-Mail extension, which I covered in very good detail in other articles. I'm going to assume that you are familiar with this extension, so if you need a refresher see this tutorial or my Flask book.
The example application that I'm going to use to illustrate the topic presents a simple web form with one text field. The user is asked to enter an email address in this field, and upon submission, the server sends a test email to this address. The form includes two submit buttons, one to send the email immediately, and another to send it after a wait of one minute. The top portion of the screenshot at the top of this article shows how this form looks.
Here is the HTML template that supports this example:
<html>
<head>
<title>Flask + Celery Examples</title>
</head>
<body>
<h1>Flask + Celery Examples</h1>
<h2>Example 1: Send Asynchronous Email</h2>
{% for message in get_flashed_messages() %}
<p style="color: red;">{{ message }}</p>
{% endfor %}
<form method="POST">
<p>Send test email to: <input type="text" name="email" value="{{ email }}"></p>
<input type="submit" name="submit" value="Send">
<input type="submit" name="submit" value="Send in 1 minute">
</form>
</body>
</html>
Hopefully you find nothing earth shattering here. Just a regular HTML form, plus the ability to show flashed messages from Flask.
The Flask-Mail extension requires some configuration, specifically the details about the email server to use when sending emails. To make things easy I use my Gmail account as email server:
# Flask-Mail configuration
app.config['MAIL_SERVER'] = 'smtp.googlemail.com'
app.config['MAIL_PORT'] = 587
app.config['MAIL_USE_TLS'] = True
app.config['MAIL_USERNAME'] = os.environ.get('MAIL_USERNAME')
app.config['MAIL_PASSWORD'] = os.environ.get('MAIL_PASSWORD')
app.config['MAIL_DEFAULT_SENDER'] = 'flask@example.com'
Note how to avoid putting my email account's credentials at risk I set them in environment variables, which I import from the application.
There is a single route to support this example:
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'GET':
return render_template('index.html', email=session.get('email', ''))
email = request.form['email']
session['email'] = email
# send the email
email_data = {
'subject': 'Hello from Flask',
'to': email,
'body': 'This is a test email sent from a background Celery task.'
}
if request.form['submit'] == 'Send':
# send right away
send_async_email.delay(email_data)
flash('Sending email to {0}'.format(email))
else:
# send in one minute
send_async_email.apply_async(args=[email_data], countdown=60)
flash('An email will be sent to {0} in one minute'.format(email))
return redirect(url_for('index'))
Once again, this is all pretty standard Flask. Since this is a very simple form, I decided to handle it without the help of an extension, so I use request.method and request.form to do all the management. I save the value that the user enters in the text field in the session, so that I can remember it after the page reloads.
The data associated with the email, which is the subject, recipient(s) and body, are stored in a dictionary. The interesting bit in this route is the sending of the email, which is handled by a Celery task called send_async_email, invoked either via delay() or apply_async() with this dictionary as an argument.
The last piece of this application is the asynchronous task that gets the job done:
@celery.task
def send_async_email(email_data):
"""Background task to send an email with Flask-Mail."""
msg = Message(email_data['subject'],
sender=app.config['MAIL_DEFAULT_SENDER'],
recipients=[email_data['to']])
msg.body = email_data['body']
with app.app_context():
mail.send(msg)
This task is decorated with celery.task to make it a background job. The function constructs a Message object from Flask-Mail using the data from the email_data dictionary. One notable thing in this function is that Flask-Mail requires an application context to run, so one needs to be created before the send() method can be invoked.
It is important to note that in this example the return value from the asynchronous call is not preserved, so the application will never know if the call succeeded or not. When you get to run this example, you can look at the output of the Celery worker to troubleshoot any problems with the sending of the email.
Complex Example: Showing Status Updates and Results
The above example is overly simple, the background job is started and then the application forgets about it. Most Celery tutorials for web development end right there, but the fact is that for many applications it is necessary for the application to monitor its background tasks and obtain results from it.
What I'm going to do now is extend the above application with a second example that shows a fictitious long running task. The user can start one or more of these long running jobs clicking a button, and the web page running in your browser uses ajax to poll the server for status updates on all these tasks. For each task the page will show a graphical status bar, a completion percentage, a status message, and when the task completes, a result value will be shown as well. You can see how all this looks in the screenshot at the top of this article.
Background Tasks with Status Updates
Let me start by showing you the background task that I'm using for this second example:
@celery.task(bind=True)
def long_task(self):
"""Background task that runs a long function with progress reports."""
verb = ['Starting up', 'Booting', 'Repairing', 'Loading', 'Checking']
adjective = ['master', 'radiant', 'silent', 'harmonic', 'fast']
noun = ['solar array', 'particle reshaper', 'cosmic ray', 'orbiter', 'bit']
message = ''
total = random.randint(10, 50)
for i in range(total):
if not message or random.random() < 0.25:
message = '{0} {1} {2}...'.format(random.choice(verb),
random.choice(adjective),
random.choice(noun))
self.update_state(state='PROGRESS',
meta={'current': i, 'total': total,
'status': message})
time.sleep(1)
return {'current': 100, 'total': 100, 'status': 'Task completed!',
'result': 42}
For this task I've added a bind=True argument in the Celery decorator. This instructs Celery to send a self argument to my function, which I can then use to record the status updates.
Since this task doesn't really do anything useful, I decided to use humorous status messages that are assembled from random verbs, adjectives and nouns. You can see the lists of non-sensical items I use to generate these messages above. Nothing wrong with having a little bit of fun, right?
The function loops for a random number of iterations between 10 and 50, so each run of the task will have a different duration. The random status message is generated on the first iteration, and then can be replaced in later iterations with a 25% chance.
The self.update_state() call is how Celery receives these task updates. There are a number of built-in states, such as STARTED, SUCCESS and so on, but Celery allows custom states as well. Here I'm using a custom state that I called PROGRESS. Attached to the state there is additional metadata, in the form of a Python dictionary that includes the current and total number of iterations and the randomly generated status message. A client can use these elements to display a nice progress bar. Each iteration sleeps for one second, to simulate some work being done.
When the loop exits, a Python dictionary is returned as the function's result. This dictionary includes the updated iteration counters, a final status message and a humorous result.
The long_task() function above runs in a Celery worker process. Below you can see the Flask application route that starts this background job:
@app.route('/longtask', methods=['POST'])
def longtask():
task = long_task.apply_async()
return jsonify({}), 202, {'Location': url_for('taskstatus',
task_id=task.id)}
As you can see the client needs to issue a POST request to /longtask to kick off one of these tasks. The server starts the task, and stores the return value. For the response I used status code 202, which is normally used in REST APIs to indicate that a request is in progress. I also added a Location header, with a URL that the client can use to obtain status information. This URL points to another Flask route called taskstatus, and has task.id as a dynamic component.
Accessing Task Status from the Flask Application
The taskstatus route referenced above is in charge of reporting status updates provided by background tasks. Here is the implementation of this route:
@app.route('/status/<task_id>')
def taskstatus(task_id):
task = long_task.AsyncResult(task_id)
if task.state == 'PENDING':
# job did not start yet
response = {
'state': task.state,
'current': 0,
'total': 1,
'status': 'Pending...'
}
elif task.state != 'FAILURE':
response = {
'state': task.state,
'current': task.info.get('current', 0),
'total': task.info.get('total', 1),
'status': task.info.get('status', '')
}
if 'result' in task.info:
response['result'] = task.info['result']
else:
# something went wrong in the background job
response = {
'state': task.state,
'current': 1,
'total': 1,
'status': str(task.info), # this is the exception raised
}
return jsonify(response)
This route generates a JSON response that includes the task state and all the values that I set in the update_state() call as the meta argument, which the client can use to build a progress bar. Unfortunately this function needs to check for a few edge conditions as well, so it ended up being a bit long. To access task data I recreate the task object, which is an instance of class AsyncResult, using the task id given in the URL.
The first if block is for when the task hasn't started yet (PENDING state). In this case there is no status information, so I make up some data. The elif block that follows is that one that returns the status information from the background task. Here the information that the task provided is accessible as task.info. If the data contains a result key, then that means that this is the final result and the task finished, so I add that result to the response as well. The else block at the end covers the possibility of an error, which Celery will report by setting a task state of "FAILURE", and in that case task.info will contain the exception raised. To handle errors I set the text of the exception as a status message.
Believe it or not, this is all it takes from the server. The rest needs to be implemented by the client, which in this example is a web page with Javascript scripting.
Client-Side Javascript
It isn't really the focus of this article to describe the Javascript portion of this example, but in case you are interested, here is some information.
For the graphical progress bar I'm using nanobar.js, which I included from a CDN. I also included jQuery, which simplifies the ajax calls significantly:
<script src="//cdnjs.cloudflare.com/ajax/libs/nanobar/0.2.1/nanobar.min.js"></script>
<script src="//cdnjs.cloudflare.com/ajax/libs/jquery/2.1.3/jquery.min.js"></script>
The button that starts a background job is connected to the following Javascript handler:
function start_long_task() {
// add task status elements
div = $('<div class="progress"><div></div><div>0%</div><div>...</div><div> </div></div><hr>');
$('#progress').append(div);
// create a progress bar
var nanobar = new Nanobar({
bg: '#44f',
target: div[0].childNodes[0]
});
// send ajax POST request to start background job
$.ajax({
type: 'POST',
url: '/longtask',
success: function(data, status, request) {
status_url = request.getResponseHeader('Location');
update_progress(status_url, nanobar, div[0]);
},
error: function() {
alert('Unexpected error');
}
});
}
This function starts by adding a few HTML elements that will be used to display the new background task's progress bar and status. This is done dynamically because the user can add any number of jobs, and each job needs to get its own set of HTML elements.
To help you understand this better, here is the structure of the added elements for a task, with comments to indicate what each div is used for:
<div class="progress">
<div></div> <-- Progress bar
<div>0%</div> <-- Percentage
<div>...</div> <-- Status message
<div> </div> <-- Result
</div>
<hr>
The start_long_task() function then instantiates the progress bar according to nanobar's documentation, and finally sends the ajax POST request to /longtask to initiate the Celery background job in the server.
When the POST ajax call returns, the callback function obtains the value of the Location header, which as you saw in the previous section is for the client to invoke to get status updates. It then calls another function, update_progress() with this status URL, the progress bar object and the root div element subtree created for the task. Below you can see this update_progress() function, which sends the status request and then updates the UI elements with the information returned by it:
function update_progress(status_url, nanobar, status_div) {
// send GET request to status URL
$.getJSON(status_url, function(data) {
// update UI
percent = parseInt(data['current'] * 100 / data['total']);
nanobar.go(percent);
$(status_div.childNodes[1]).text(percent + '%');
$(status_div.childNodes[2]).text(data['status']);
if (data['state'] != 'PENDING' && data['state'] != 'PROGRESS') {
if ('result' in data) {
// show result
$(status_div.childNodes[3]).text('Result: ' + data['result']);
}
else {
// something unexpected happened
$(status_div.childNodes[3]).text('Result: ' + data['state']);
}
}
else {
// rerun in 2 seconds
setTimeout(function() {
update_progress(status_url, nanobar, status_div);
}, 2000);
}
});
}
This function sends the GET request to the status URL, and when a response is received it updates the different HTML elements for the task. If the background task completed and a result is available then it is added to the page. If there is no result then that means that the task ended due to an error, so the task state, which is going to be FAILURE, is shown as result.
When the server is still running the job I need to continue polling the task status and updating the UI. To achieve this I set a timer to call the function again in two seconds. This will continue until the Celery task completes.
A Celery worker runs as many concurrent jobs as there are CPUs by default, so when you play with this example make sure you start a large number of tasks to see how Celery keeps jobs in PENDING state until the worker can take it.
Running the Examples
If you made it all the way here without running the example application, then it is now time for you to try all this Celery goodness. Go ahead and clone the Github repository, create a virtual environment, and populate it:
$ git clone https://github.com/miguelgrinberg/flask-celery-example.git
$ cd flask-celery-example
$ virtualenv venv
$ source venv/bin/activate
(venv) $ pip install -r requirements.txt
Note that the requirements.txt file included with this repository contains Flask, Flask-Mail, Celery and the Redis client, along with all their dependencies.
Now you need to run the three processes required by this application, so the easiest way is to open three terminal windows. On the first terminal run Redis. You can just install Redis according to the download instructions for your operating system, but if you are on a Linux or OS X machine, I have included a small script that downloads, compiles and runs Redis as a private server:
$ ./run-redis.sh
Note that for the above script to work you need to have gcc installed. Also note that the above command is blocking, Redis will start in the foreground.
On the second terminal run a Celery worker. This is done with the celery command, which is installed in your virtual environment. Since this is the process that will be sending out emails, the MAIL_USERNAME and MAIL_PASSWORD environment variables must be set to a valid Gmail account before starting the worker:
$ export MAIL_USERNAME=<your-gmail-username>
$ export MAIL_PASSWORD=<your-gmail-password>
$ source venv/bin/activate
(venv) $ celery worker -A app.celery --loglevel=info
The -A option gives Celery the application module and the Celery instance, and --loglevel=info makes the logging more verbose, which can sometimes be useful in diagnosing problems.
Finally, on the third terminal window run the Flask application, also from the virtual environment:
$ source venv/bin/activate
(venv) $ python app.py
Now you can navigate to http://localhost:5000/ in your web browser and try the examples!
Conclusion
Unfortunately when working with Celery you have to take a few more steps than simply sending a job to a background thread, but the benefits in flexibility and scalability are hard to ignore. In this article I tried to go beyond the "let's start a background job" example and give you a more complete and realistic portrait of what using Celery might entail. I sincerely hope I haven't scared you with too much information!
As always, feel free to write down any questions or comments below.
Miguel
Become a Patron!
Hello, and thank you for visiting my blog! If you enjoyed this article, please consider supporting my work on this blog on Patreon!

-
#1 Pete Forman said
There is a typo in the h2 of your HTML template: Asnychronous
The initial screenshot is okay though.
-
#2 Miguel Grinberg said
@Pete: yes, I thought I got rid of the typo everywhere, but looks like I missed one. Thanks!
-
#3 Jason Helland said
Like all of your work, another well thought out example and nicely done code. Thanks for all the good work you've done with Flask; I've learned a lot.
If anyone is interested, I modified this example to use Flask-SocketIO as an exercise in learning that module. Instead of the client polling, the celery task can notify the client via a post to the Flask app.
-
#4 Miguel Grinberg said
@Jason: Very nice!
-
#5 Andy said
Brilliant Miguel. These more fully realistic examples are fantastic.
-
#6 Patricio said
Miguel, thank you for posting this how-to ! I wonder if celery or this toolset is able to persist its data. I mean, what happens if, on a long task that received some kind of existing object, the flask server is stopped and the app is restarted ? I suppose the messages are still on the broker but is everything able to resume where it was, to restart the function call or to delete everything ?
-
#7 Miguel Grinberg said
@Patricio: If only the server needs to be restarted then I guess as long as the task IDs were preserved somewhere you can ask for status on tasks that were started by the previous server run. Any tasks that are being executed by the worker(s) will continue normally, the web server restarting has no effect on them.
But note that in many cases the code that runs in the workers is shared with code running in the web server, so depending on the change you may also need to restart the Celery workers, in which case I think it is best to assume any ongoing tasks did not complete.
-
#8 Ax3 said
Hello, and thanks for tutorial!
My question is: how do I pass arguments to the long task? For example, server received some "post" data, how do I pass it to the long task function?
Thanks in advance!
-
#9 Miguel Grinberg said
@Ax3: You can have arguments on the background function, then you pass values for these arguments when you call it. See the email example above.
-
#10 Michael said
This was another great tutorial. However, I remain a little confused about how to integrate celery into a larger app, say structured along the lines of Flasky. It almost seems like two different version of celery are needed or an extension to do an init_app thing. Any suggestions would be greatly appreciated.
-
#11 Miguel Grinberg said
@Michael: Celery does not need an init_app function, it does not use the app instance for anything. Note that the constructor takes the application's name (in my example I pass app.name) and the broker URL. If you put the app name as a string, then there is no dependency on the flask app instance.
-
#12 Sebastian Cheung said
Not sure how to resolve this, but upon launching the browser:
Exception in thread Thread-2:
Traceback (most recent call last):
File "/Users/me/anaconda/envs/oracle/lib/python2.7/threading.py", line 810, in bootstrap_inner
self.run()
File "/Users/me/anaconda/envs/oracle/lib/python2.7/threading.py", line 763, in run
self.__target(self.__args, self.__kwargs)
File "/Users/me/PycharmProjects/celery-socketio/app.py", line 47, in background_celery_thread
my_monitor(app)
File "/Users/me/PycharmProjects/celery-socketio/app.py", line 41, in my_monitor
'': announce_tasks,
File "/Users/me/anaconda/envs/oracle/lib/python2.7/site-packages/celery/events/__init.py", line 287, in init
self.channel = maybe_channel(channel)
File "/Users/me/anaconda/envs/oracle/lib/python2.7/site-packages/kombu/connection.py", line 1054, in maybe_channel
return channel.default_channel
File "/Users/me/anaconda/envs/oracle/lib/python2.7/site-packages/kombu/connection.py", line 756, in default_channel
self.connection
File "/Users/me/anaconda/envs/oracle/lib/python2.7/site-packages/kombu/connection.py", line 741, in connection
self._connection = self._establish_connection()
File "/Users/me/anaconda/envs/oracle/lib/python2.7/site-packages/kombu/connection.py", line 696, in _establish_connection
conn = self.transport.establish_connection()
File "/Users/me/anaconda/envs/oracle/lib/python2.7/site-packages/kombu/transport/pyamqp.py", line 112, in establish_connection
conn = self.Connection(**opts)
File "/Users/me/anaconda/envs/oracle/lib/python2.7/site-packages/amqp/connection.py", line 165, in init
self.transport = self.Transport(host, connect_timeout, ssl)
File "/Users/me/anaconda/envs/oracle/lib/python2.7/site-packages/amqp/connection.py", line 186, in Transport
return create_transport(host, connect_timeout, ssl)
File "/Users/me/anaconda/envs/oracle/lib/python2.7/site-packages/amqp/transport.py", line 299, in create_transport
return TCPTransport(host, connect_timeout)
File "/Users/me/anaconda/envs/oracle/lib/python2.7/site-packages/amqp/transport.py", line 95, in init
raise socket.error(last_err)
error: [Errno 61] Connection refused -
#13 Miguel Grinberg said
@Sebastian: Are you running a celery worker process?
-
#14 Daniel Jorge said
Hi, Miguel. Great tutorial!
In the complex example, supose I start a long running task (5 min or so) and then close the browser when it is at around 50% completion... I know the task will keep runing on the server, but I want to be able to reopen my browser and "re-capture" THAT task status, which will probably be at around 60% completion now... I don't know if I'm being clear enough... I hope so...
Thanks!
-
#15 Miguel Grinberg said
@Daniel: All you need to do is save the "status_url" so that you can still have it when you reopen the browser. You can put it in a cookie, for example, or write it to the user session, which ends up in a cookie, also.
-
#16 Biboufr said
Hi Miguel, thank your for the tutorial.
I have a question that I posted here (http://stackoverflow.com/questions/29371514/celery-update-state-inside-class-method) but got no answers so I'm going to ask you here : how do you use the 'update_state' method inside a class and not directly in the binded function ?
Cheers ! -
#17 Miguel Grinberg said
@Biboufr: I replied on stack overflow.
-
#18 Raymond said
Hi Miguel,
I met a little question here.
I did exactly as your instruction but when I start the long task, those task can only processed one by one instead of running at the same time. Is that may be cause of my virtual machine only have 1 processor for worker?
Thank you! -
#19 Miguel Grinberg said
@Raymond: A celery worker by default can only execute a job per CPU, so yes, if you have a single CPU then you can only have one job at a time. To be able to handle more concurrent jobs you can run more workers either in the same host or in a different one.
-
#20 Jonathan said
Hi, I'm trying to use celery in my Flask app.
It (the app) was built by following your book "Flask Web Development". And one of my blueprints uses task from celery. So I'm initializing celery twice: first time, when I'm connecting to this blueprint. And this works well. But when I'm trying to run celery, it also initialises application, than blueprint, then itself again. So here I've got a cycle import. Could you advice how to change my application to break this cycle?
Here is the code:
http://stackoverflow.com/questions/29670961/flask-blueprints-uses-celery-task-and-got-cycle-importthanks in advance
-
#21 Miguel Grinberg said
@Jonathan: just replied to the SO question.
-
#22 spitz said
Great article! Can you mention something about using the use of sqlalchemy models within the @celery.task? Basically, I'm having a issue that model updates taking place within Flask are not updated in Celery. Basically, I have to do a "sudo service celery restart" to sync the models.
-
#23 Miguel Grinberg said
By "sync the models" you mean changes to the database schema, or just new data that is added without changing the schema? If the former, then yes, it is expected that when the model structure changes you have to restart every application that uses those models.
-
#24 spitz said
It would be the latter. For example, when a user uploads a file through @app.route I process the files and store file details (name, path, extension, etc.) to the Uploads table, however, if the user then runs an @celery.task that accesses Uploads the file is not found. If I do a "sudo service celery restart" the file is found and the task complete successfully. Today I added "with app.app_context():" and it seems that the issue is fixed itself.... Could this be due to celery running as an independent process (different user) than the Flask app?
-
#25 Miguel Grinberg said
@spitz: Hmm, this is pretty odd. It's difficult to diagnose without seeing the code, if you have the code available publicly I'd like to take a look at it to see if I can figure out what happened.















