Ignore All Web Performance Benchmarks, Including This One
Posted by
on underA couple of months ago there was an article titled Async Python is Not Faster making the rounds on social media. In it, the author Cal Paterson made the point that contrary to popular belief, asynchronous web frameworks are not only "not faster" than their traditional synchronous counterparts, but they are also slower. He supports this by showing the results of a fairly complete benchmark that he implemented.
I wish things were as simple as this author puts them in his blog post, but the fact is that measuring web application performance is incredibly complex and he's got a few things wrong, both in the implementation of the benchmark and in his interpretation of the results.
In this article you can see the results of my effort in understanding and fixing this benchmark, re-running it, and finally arriving at a shocking revelation.
The Benchmark Results
Before I delve into the gory details, I assume you are anxious to see what the results of the benchmark are. These are the results that I obtained when running this benchmark, after I fixed all the problems I've found in it. I have also added several more frameworks that I was particularly interested in:
| Framework | Web Server | Type | Wrk | Tput | P50 | P99 | #DB |
|---|---|---|---|---|---|---|---|
| Falcon | Meinheld | Async / Greenlet | 6 | 1.60 | 94 | 163 | 100 |
| Bottle | Meinheld | Async / Greenlet | 6 | 1.58 | 96 | 167 | 100 |
| Flask | Meinheld | Async / Greenlet | 6 | 1.43 | 105 | 182 | 100 |
| Aiohttp | Aiohttp | Async / Coroutine | 6 | 1.38 | 108 | 196 | 91 |
| Falcon | Gevent | Async / Greenlet | 6 | 1.37 | 107 | 223 | 100 |
| Sanic | Sanic | Async / Coroutine | 6 | 1.34 | 111 | 220 | 85 |
| Bottle | Gevent | Async / Greenlet | 6 | 1.31 | 114 | 220 | 100 |
| Starlette | Uvicorn | Async / Coroutine | 6 | 1.31 | 113 | 236 | 87 |
| Tornado | Tornado | Async / Coroutine | 6 | 1.25 | 120 | 230 | 93 |
| Flask | Gevent | Async / Greenlet | 6 | 1.22 | 122 | 241 | 98 |
| FastAPI | Uvicorn | Async / Coroutine | 6 | 1.21 | 124 | 245 | 86 |
| Sanic | Uvicorn | Async / Coroutine | 6 | 1.18 | 127 | 251 | 87 |
| Quart | Uvicorn | Async / Coroutine | 6 | 1.13 | 132 | 252 | 79 |
| Aioflask | Uvicorn | Async / Coroutine | 6 | 1.11 | 135 | 269 | 80 |
| Falcon | uWSGI | Sync | 19 | 1.04 | 146 | 179 | 19 |
| Bottle | uWSGI | Sync | 19 | 1.03 | 148 | 184 | 19 |
| Falcon | Gunicorn | Sync | 19 | 1.02 | 149 | 190 | 19 |
| Flask | uWSGI | Sync | 19 | 1.01 | 151 | 182 | 19 |
| Flask | Gunicorn | Sync | 19 | 1.00 | 153 | 184 | 19 |
| Bottle | Gunicorn | Sync | 19 | 0.99 | 153 | 208 | 19 |
| Quart | Hypercorn | Async / Coroutine | 6 | 0.91 | 161 | 336 | 69 |
| Framework | Web Server | Type | Wrk | Tput | P50 | P99 | #DB |
|---|---|---|---|---|---|---|---|
| Bottle | Meinheld | Async / Greenlet | 6 | 1.38 | 85 | 1136 | 100 |
| Falcon | Meinheld | Async / Greenlet | 6 | 1.38 | 84 | 1134 | 99 |
| Sanic | Sanic | Async / Coroutine | 6 | 1.24 | 95 | 1155 | 83 |
| Flask | Meinheld | Async / Greenlet | 6 | 1.23 | 88 | 1124 | 97 |
| Starlette | Uvicorn | Async / Coroutine | 6 | 1.23 | 102 | 1146 | 82 |
| Bottle | Gevent | Async / Greenlet | 6 | 1.21 | 89 | 1162 | 95 |
| Aiohttp | Aiohttp | Async / Coroutine | 6 | 1.20 | 95 | 1153 | 80 |
| Flask | Gevent | Async / Greenlet | 6 | 1.16 | 103 | 1165 | 97 |
| Sanic | Uvicorn | Async / Coroutine | 6 | 1.14 | 95 | 1179 | 83 |
| Tornado | Tornado | Async / Coroutine | 6 | 1.12 | 91 | 1170 | 82 |
| Falcon | Gevent | Async / Greenlet | 6 | 1.12 | 82 | 1144 | 96 |
| FastAPI | Uvicorn | Async / Coroutine | 6 | 1.08 | 88 | 1197 | 77 |
| Aioflask | Uvicorn | Async / Coroutine | 6 | 1.08 | 116 | 1167 | 83 |
| Falcon | uWSGI | Sync | 19 | 1.07 | 152 | 183 | 19 |
| Quart | Uvicorn | Async / Coroutine | 6 | 1.05 | 116 | 1167 | 74 |
| Bottle | uWSGI | Sync | 19 | 1.05 | 154 | 193 | 19 |
| Bottle | Gunicorn | Sync | 19 | 1.02 | 159 | 187 | 19 |
| Flask | Gunicorn | Sync | 19 | 1.00 | 163 | 192 | 19 |
| Flask | uWSGI | Sync | 19 | 0.94 | 157 | 1166 | 19 |
| Falcon | Gunicorn | Sync | 19 | 0.91 | 159 | 1183 | 19 |
| Quart | Hypercorn | Async / Coroutine | 6 | 0.90 | 150 | 1216 | 64 |
Note that the above results were generated during an update of this article on October 27th, 2020 that addressed an issue with the P99 numbers. In the spirit of full transparency, you can click here to view the results that were published with the original article. Click here to restore the most up to date results.
Notes regarding these results:
- This benchmark shows performance under a constant load of one hundred clients.
- There are three types of tests: Sync, Async / Coroutine and Async / Greenlet. If you need to understand what the differences between these types are, check out my Sync vs. Async Python article.
- I used two different worker configurations. For async tests I used 6 workers (one per CPU). For sync tests I used 19 workers. I arrived at these numbers by testing different configurations to maximize performance.
- All the asyncio tests use uvloop for best performance.
- Instead of reporting throughput as requests per second, I use the Flask+Gunicorn test as the baseline, and report the throughput for each test as a multiplier from this baseline. For example, a throughput of 2.0 means "twice as fast as Flask+Gunicorn" and a throughput of 0.5 means "half as fast (or twice as slow) as Flask+Gunicorn".
- P50 is the 50th percentile or median of the request processing time in milliseconds. In other words, 50% of the requests sent during the test were completed in less than this time.
- P99 is the 99th percentile of the request processing time in milliseconds. You can think of this number as a longest a request took to be processed, with the outliers removed.
- The #DB column shows the maximum number of database sessions used by each test. Per configuration there were 100 sessions available. Sync tests are obviously limited to one session per worker.
Note that you can sort the data in every possible way by clicking on the table headers. When you are done, keep on reading to understand what do these numbers really mean (and why none of this matters in practice!).
What Does The Benchmark Do?
The benchmark consists on running a web application under load, and measuring the performance. The test is repeated for many different configurations of web servers and web frameworks to determine how all these tools perform under the same conditions.
Below you can see a diagram of what the test does. In this diagram, the gray boxes are constant, while the red boxes represent the parts of the system in which the different implementations that are being evaluated are plugged in.
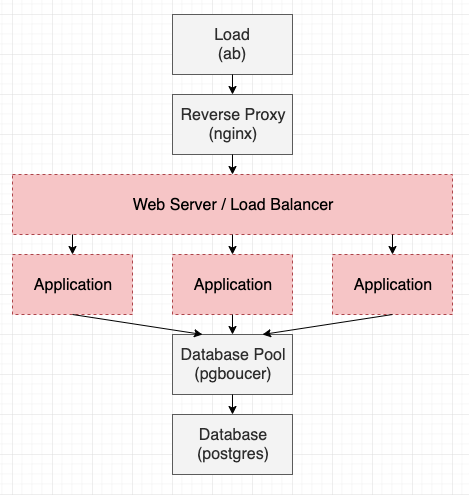
- The load generator is the process that generates client connections. This is done with Apache Bench (ab).
- Requests are received by a reverse proxy, which is the only public interface. The nginx server provides this functionality.
- The web server and load balancer accepts requests from the reverse proxy and dispatches them to one of several web application workers.
- The application component is where requests are handled.
- The database pool is a service that manages a pool of database connections. In this test this task is done by pgbouncer.
- The database is the actual storage service, which is a PostgresSQL instance.
The original benchmark had a nice variety of web servers. I've added a couple more that were interesting to me. The complete list of web servers that I tested is shown below.
| Server | Type | Language |
|---|---|---|
| Gunicorn | Sync | Python |
| uWSGI | Sync | C |
| Gevent | Async / Greenlet | Python |
| Meinheld | Async / Greenlet | C |
| Tornado | Async / Coroutine | Python |
| Uvicorn | Async / Coroutine | Python |
| Aiohttp | Async / Coroutine | Python |
| Sanic | Async / Coroutine | Python |
| Hypercorn | Async / Coroutine | Python |
For the application components, a small microservice that performs a database query and returns the result as a JSON response is used. So that you have a better idea of what the test involves, below you can see the Flask and Aiohttp implementations of this service:
import flask
import json
from sync_db import get_row
app = flask.Flask("python-web-perf")
@app.route("/test")
def test():
a, b = get_row()
return json.dumps({"a": str(a).zfill(10), "b": b})
import json
from aiohttp import web
from async_db import get_row
async def handle(request):
a, b = await get_row()
return web.Response(text=json.dumps({"a": str(a).zfill(10), "b": b}))
app = web.Application()
app.add_routes([web.get('/test', handle)])
The get_row() function runs a query on a database loaded with random data. There are two implementations of this function, one with the psycopg2 package for standard Python, and another one with aiopg for asyncio tests. For greenlet tests, psycopg2 is properly patched so that it does not block the async loop (this was an important oversight in the original benchmark).
The implementations of this application that I tested are based on the following web frameworks:
| Framework | Platform | Gateway interface |
|---|---|---|
| Flask | Standard Python | WSGI |
| Bottle | Standard Pyhon | WSGI |
| Falcon | Standard Pyhon | WSGI |
| Aiohttp | asyncio | Custom |
| Sanic | asyncio | Custom or ASGI |
| Quart | asyncio | ASGI |
| Starlette | asyncio | ASGI |
| Tornado | asyncio | Custom |
| FastAPI | asyncio | ASGI |
| Aioflask | asyncio | ASGI |
I have not tested every possible pairing of a web server and an application, mainly because some combinations do not work together, but also because I did not want to waste testing time on combinations that are weird, uncommon or not interesting.
If you are familiar with the original benchmark, here is the list of differences in my own set up:
- I have executed all the tests on real hardware. The original benchmark used a cloud server, which is not a good idea because CPU performance in virtualized servers is constantly changing and is dependent on usage by other servers that are colocated with yours on the same physical host.
- I have used Docker containers to host all the components in the test. This is just for convenience, I do not know what was the setup in the original benchmark.
- I have removed the session pool at the application layer, since
pgbounceralready provides session pooling. This solves an indirect problem where the application pools for sync and async tests were configured differently. In my test there are 100 sessions available to be distributed among all the application workers. - The database query issued in the original benchmark was a simple search by primary key. To make the test more realistic I made the query slightly slower by adding a short delay to it. I understand that this is an extremely subjective area and many will disagree with this change, but what I observed is that with such quick queries there wasn't much opportunity for concurrency.
- I mentioned above that I patched
psycopg2to work asynchronously when used with a greenlet framework. This was omitted in the original benchmark. - The
aiohttptest in the original benchmark used the standard loop fromasyncioinstead of the one fromuvloop.
What Do These Results Mean?
There are a few observations that can be made from the results that I obtained, but I encourage you to do your own analysis of the data and question everything. Unlike most benchmark authors, I do not have an agenda, I'm only interested in the truth. If you find any mistakes, please reach out and let me know.
I bet most of you are surprised that the best performing test managed a mere 60% performance increase over a standard Flask/Gunicorn deployment. There are certainly performance variations between the different servers and frameworks, but they are not that large, right? Remember this the next time you look at a too-good-to-be-true benchmark published by an asyncio framework author!
The async solutions (with the exception of the Hypercorn server which appears to be extremely slow) clearly perform better than the sync ones on this test. You can see that overall the sync tests are all towards the bottom of the list in throughput, and all very close to the Flask/Gunicorn baseline. Note that the author of the original benchmark refers to greenlet tests as sync for some strange reason, giving more importance to the coding style in which the application is written than to the method concurrency is achieved.
If you look at the original benchmark results and compare them against mine, you may think these are not coming from the same benchmark. While the results aren't a complete inverse, in the original results the sync tests fared much better than in mine. I believe the reason to be that the database query issued in the original benchmark was extremely simple, so simple that there was little or no gain in running multiple queries in parallel. This puts the async tests at a disadvantage, since async performs the best when the tasks are I/O bound and can overlap. As stated above, my version of this benchmark uses a slower query to make this a more realistic scenario.
One thing the two benchmarks have in common is that Meinheld tests did very well in both. Can you guess why? Meinheld is written in C, while every other async server is written in Python. That matters.
Gevent tests did reasonably well in my benchmark and terribly in the original one. This is because the author forgot to patch the psycopg2 package so that it becomes non-blocking under greenlets.
Conversely, uWSGI tests did well in the original benchmark, and just average in mine. This is odd, since uWSGI is also a C server, so it should have done better. I believe using longer database queries has a direct effect on this. When the application does more work, the time used by the web server has less overall influence. In the case of async tests, a C server such as Meinheld matters a lot because it uses its own the loop and performs all the context-switching work. In a sync server, where the OS does the context-switching, there is less expensive work that can be optimized in C.
The P50 and P99 numbers are much higher in my results, in part because my test system is probably slower, but also because the database queries that I'm issuing take longer to complete and this translates into longer request handling times. The original benchmark just queried a row by its primary key, which is extremely fast and not at all representative of a real-world database use.
Some other conclusions I make from looking at my own benchmark:
- Looking at the three sync frameworks, Falcon and Bottle appear to be slightly faster than Flask, but really not by a margin large enough to warrant switching, in my opinion.
- Greenlets are awesome! Not only they have the best performing asynchronous web server, but they also allow you to write your code in standard Python using familiar frameworks such as Flask, Django, Bottle, etc.
- I'm thrilled to find that my Aioflask experiment performs better than standard Flask, and that it is in the same performance level as Quart. I guess I'm going to have to finish it.
Benchmarks Are Unreliable
I thought it was curious that due to a few bugs and errors of interpretation, this benchmark convinced the original author that sync Python is faster than async. I wonder if he already had this belief before creating the benchmark, and if that belief is what led him to make these unintentional mistakes that veered the benchmark results in the direction he wanted.
If we accept that this is possible, shouldn't we be worried that this is happening to me as well? Could I have been fixing this benchmark not for correctness and accuracy, but just so that it agrees more with my views than with his? Some of the fixes that I've made are really bugs. For example, not patching psycopg2 when using greenlet servers cannot be defended as a choice, that is a clear cut bug that even the benchmark author could not justify. But what about other changes I've made that are more in a gray area, like how long the database query should take?
As a fun exercise, I decided to see if I could reconfigure this benchmark to show completely different results, while obviously preserving its correctness. The options that I had to play with are summarized in the following table, where you can see the configuration used in the original and my own version of the benchmark, along with the changes I would make if I wanted to tip the scale towards async or towards sync:
| Option | Original | My Benchmark | Better Async | Better Sync |
|---|---|---|---|---|
| Workers | Variable | Sync: 19 Async: 6 |
Sync: 19 Async: 6 |
Sync: 19 Async: 6 |
| Max database sessions | 4 per worker | 100 total | 100 total | 19 total |
| Database query delay | None | 20ms | 40ms | 10ms |
| Client connections | 100 | 100 | 400 | 19 |
Let me explain how changes to these four configuration variables would affect the tests:
- I decided to keep the number of workers the same, because by experimentation I have determined that these numbers were the best for performance on my test system. To me it would feel dishonest if I changed these numbers to less optimal values.
- Sync tests use one database session per worker, so any amount of sessions that is equal to or higher than the worker count results in similar performance. For async tests more sessions allow for more requests to issue their queries in parallel, so reducing this number is a sure way to affect their performance.
- The amount of I/O performed by the requests determine the balance between the I/O and CPU bound characteristics of the benchmark. When there is more I/O, async servers can still have good CPU utilization due to their high concurrency. For sync servers, on the other side, slow I/O means requests have to wait in a queue for longer until workers free up.
- Async tests can scale freely to large number of concurrent tasks, while sync tests have a fixed concurrency that is determined by the number of workers. Higher numbers of client connections hurt sync servers much more than async, so this is an easy way to favor one or the other.
Are you ready to be amazed? Below you can see a table that compares the throughput results I shared at the beginning of this article to the numbers I obtained by reconfiguring the benchmark for the two scenarios I just discussed. Click on the table headers to sort.
| Framework | Web Server | Type | My Results | Better Async | Better Sync |
|---|---|---|---|---|---|
| Falcon | Meinheld | Async / Greenlet | 1.60 | 5.17 | 1.12 |
| Bottle | Meinheld | Async / Greenlet | 1.58 | 5.56 | 1.13 |
| Flask | Meinheld | Async / Greenlet | 1.43 | 5.27 | 1.06 |
| Aiohttp | Aiohttp | Async / Coroutine | 1.38 | 4.79 | 1.27 |
| Falcon | Gevent | Async / Greenlet | 1.37 | 4.66 | 0.99 |
| Sanic | Sanic | Async / Coroutine | 1.34 | 4.58 | 1.09 |
| Bottle | Gevent | Async / Greenlet | 1.31 | 4.59 | 1.18 |
| Starlette | Uvicorn | Async / Coroutine | 1.31 | 4.36 | 1.13 |
| Tornado | Tornado | Async / Coroutine | 1.25 | 4.19 | 1.03 |
| Flask | Gevent | Async / Greenlet | 1.22 | 4.54 | 1.01 |
| FastAPI | Uvicorn | Async / Coroutine | 1.21 | 4.33 | 1.02 |
| Sanic | Uvicorn | Async / Coroutine | 1.18 | 4.40 | 1.03 |
| Quart | Uvicorn | Async / Coroutine | 1.13 | 3.99 | 0.99 |
| Aioflask | Uvicorn | Async / Coroutine | 1.11 | 3.57 | 1.07 |
| Falcon | uWSGI | Sync | 1.04 | 1.00 | 1.43 |
| Bottle | uWSGI | Sync | 1.03 | 0.90 | 1.35 |
| Falcon | Gunicorn | Sync | 1.02 | 1.00 | 1.11 |
| Flask | uWSGI | Sync | 1.09 | 1.01 | 1.26 |
| Flask | Gunicorn | Sync | 1.00 | 1.00 | 1.00 |
| Bottle | Gunicorn | Sync | 1.04 | 0.99 | 1.11 |
| Quart | Hypercorn | Async / Coroutine | 0.91 | 3.24 | 0.80 |
Isn't this mindblowing? Remember that the benchmark is always the same, all I'm doing is changing configuration parameters.
The "Better Async" benchmark shows that all sync tests are near the 1.0 baseline of the Flask/Gunicorn test, while the async tests are 3x to 6x times faster. Even the Hypercorn test, which was very slow in my benchmark, scored a very decent grade. The "Better Sync" benchmark shows the uWSGI tests doing better than the rest, and while most of the async tests ended up above 1.0, looking at these results would not excite anyone into going async.
Conclusion
I hope this article helped you realize now that the benchmark game is rigged. I could easily make reasonably sounding arguments in favor of any of these sets of results, which is exactly what every person releasing a benchmark does. I don't mean to say that benchmark authors are dishonest, in fact I believe most aren't. It's just that it is very difficult to set your personal views aside and be objective when constructing a benchmark and analyzing its results.
As I state in the title, I think the best advice I can give you is to understand the strengths async and sync solutions have and make a decision based on that instead of on what some benchmark says. Once you know which model works best for you, remember that the difference in performance between different frameworks or web servers isn't going to be very significant, so choose the tools that make you more productive!
If you are interested in playing with my version of this benchmark, you can find it on this GitHub repository.
Become a Patron!
Hello, and thank you for visiting my blog! If you enjoyed this article, please consider supporting my work on this blog on Patreon!

-
#1 Val said
Use for db request for example:
SELECT pg_sleep(0.2);
:) -
#2 Miguel Grinberg said
@Val: first of all, you may need to look into optimizing your database(s). ;-)
Second, these numbers are arbitrary, the only way to model a real-world app is to use a real-world app. That's the point I'm trying to make, these benchmarks don't really matter at all, you can pick the right numbers to make them say whatever you want.
-
#3 SeungWon said
I started flask 4 years ago all thanks to you, and again you amazed me by incredible insight this post has!!!
I once chose cherrypy over nginx because of some benchmark and from then I started to have a idea that maybe benchmark is not everything, whoa. you clears my mind, thank you -
#4 Marek Marczak said
Actually aiopg driver performs quite slow compared to asyncpg. It would be a large gap between sync and async servers if you have used asyncpg as db driver. I think you konw about this .
-
#5 Miguel Grinberg said
@Marek: sorry, but I disagree. I'm running a database query, and a simple one at that. Changing the driver is not going to make any significant difference. But if you feel otherwise, I have published all the code, so you are welcome to measure the difference.
-
#6 Someone said
It would be interesting to run the tests under Pypy
-
#7 Miguel Grinberg said
@Someone: all the code is on GitHub...
-
#8 Gerardo said
Great analysis; it will be interesting to re-run all the test for the 1-year anniversary.
I am doing some testing with a few of the frameworks and servers, and the new versions have decreased performance compared to the old ones (eg. Falcon v2/v3).
Also to include some typical combination used in production like gunicorn+uvicorn and gunicorn+meinheld.
;)
-G -
#9 Miguel Grinberg said
@Gerardo: what do you expect will be different a year later? Sure, some frameworks will move a bit up, others will move down. How does that change anything?
-
#10 Mark O. said
What did you use to build out this blog website? I guess Flask?
-
#11 Miguel Grinberg said
@Mark: of course!
-
#12 Dustin said
The most interesting thing to me is that the delta is so small. In fact, even in the original article it's small enough that I don't think it really matters for the vast majority of projects which framework you use.
-
#13 Miguel Grinberg said
@Dustin: You are 100% correct on this. The differences are so small that when you add a real application they don't really matter at all.
-
#14 Sergey said
I propose a bit different bench. In real life you are trying to get maximum from the hardware you have, and framework plays a role on how able you are to do this.
A simple example - sync uses 19 workers while async uses only 6. Every worker is a process, and the typical python process consumes about 75-80 MB of RAM. So basically it is 450-480 MB for async vs 1425-1520 MB for sync. Is this difference too small? I think 1 GB of RAM is a good difference, cause you can run a redis cache on it, and speed-up the async version even more. Or just downgrade the hardware, to pay 10$ less for it
And exactly the same with CPU. You where not measuring the CPU load, but async is using way less CPU, so you can use freed CPU time with some benefit (which obviously depends on what is you app doing in general)
-
#15 Miguel Grinberg said
@Sergey: Sorry, but your analysis isn't accurate.
the typical python process consumes about 75-80 MB of RAM
That's a gross simplification. An async process that is executing hundreds of concurrent requests uses a lot more RAM than a sync process executing a single request at a time. You can't really run a RAM comparison the way you do it. In general you are going to find that a sync worker uses more RAM per request than an async worker, but the difference isn't as big as you make it look with your simplistic back of the envelope math.
async is using way less CPU
Wrong again. The async tests were actually all pegging the CPU at 100% or close. The sync tests were the ones that had some CPU left over cycles, because they were not able to run enough requests in parallel to saturate the CPU. Basically CPU load is about the same per request, sync or async.
There's really no substantial benefit to using one or the other, which is the point I'm trying to make in this article!
-
#16 Sergey said
Obviously, it's not accurate, cause it's just an example to give the point of what I mean. :)
It's wrong as well to compare RAM usage of hundreds of async coroutine requests with one single sync request, cause in the bench they have ~ same Tput, so we need to compare 1 worker with 3 async reqs vs. 3 workers with 3 sync reqs (1-per-worker). So my bet is that overhead of 3 coroutines over 3 sync reqs is a way-way smaller than overhead of 3-workers over 1-worker, because a worker is a full process. And this difference grows even higher when we step out from the "Hello World" app to something bigger.
On the link below the measure gave a 0.55 KiB per coroutine memory overhead. So 3 async reqs give us about 1.65 KiB RAM overhead. Which is not that big, and drastically smaller than +2 running processes.
https://stackoverflow.com/questions/55761652/How can they use same amount of CPU? This affirmation denies the whole idea of async coroutines. The flow of the request has few parts: pre-IO & IO-waiting & post-IO. In the sync req all of them are holding CPU from doing other tasks, while async req is dropping the hold on the IO-waiting part. How can "pre-IO + IO-waiting + post-IO" be equal with "pre-IO + post-IO"? That sounds weird.
-
#17 Miguel Grinberg said
@Sergey:
It's wrong as well to compare RAM usage of hundreds of async coroutine requests with one single sync request
Of course. This is what I said above: "In general you are going to find that a sync worker uses more RAM per request than an async worker". Note the "per request" qualifier, which makes the comparison more useful. In any case, we agree, sync uses more RAM "per request" than async. If RAM was the only consideration, then async wins fair and square. But it isn't, right? There's a lot of other things that I also consider when deciding what to use. When RAM is not the bottleneck, it makes no sense to try to optimize RAM usage.
In the sync req all of them are holding CPU from doing other tasks
Holding the CPU is not the same as using the CPU. When the CPU is held by thread within a process, the operating system makes the CPU available to other threads in the same process and to other processes. This is explained in this article, and it forms the basis of concurrency with processes and threads.
I'm really lost at this point, as I'm not really sure what is the point that you are trying to make. I honestly don't enjoy this type of discussion. Clearly you like async, so you should use async and feel good that you've made the best choice for yourself. I prefer to keep an open mind and understand that both approaches have pros and cons. But I don't really feel it is my job to convince you. If you don't agree with my reasoning, which is well explained in the article, then let's just disagree. OK?
-
#18 Yzy said
I don't think async python is faster in any cases, but async python can handle more connections :)
-
#19 Stiffer Doroskevich said
Miguel! Thanks for sharing this, and also for being open-minded, that is how we grow!
Every Framework/server/tool has his own context for what it was created...
So, like you said, "ignore al web performance benchmarks including this one".
I'm happy to understand more now how each one performs, doing this kind of tests takes a lot of time! And now everyone reading this doesn't have to.Greetings from Paraguay.
-
#20 Ondřej Tůma said
Thank you very much for your research! I found only one free space in your test, and that is combination uWsgi + Gevent. uWsgi has support for Gevent, and that should bring same results just like Meinheld server, which is probably death project more then uWsgi.
-
#21 John Byrne said
Miguel, thanks so much for this analysis.
I see the discussion about RAM utilization, and very much agree with your general statement that RAM utilization isn't going to be that different per request between async and sync. Of course this depends on the program; the non-static memory utilization per request would be about the same I assume, whereas the static parts of the program can be shared better across so many threads. In any case, publishing the RAM and CPU utilization for the tests would be interesting if you ever re-run this.
I was struck by the large difference in DB connections. What did the DB server utilization (eg. memory) look like? This looks like an example of the 'back pressure' problem discussed in one of the articles you link to.
Nice job!
-
#22 Miguel Grinberg said
@John: I have made all the code for this benchmark available, so you are welcome to play with it and extract any metrics. On my part I think I have said what I wanted to say, which is that none of these differences matter much, so I'm unlikely to ever pick this up again.















